Z-Image AI クリエーションギャラリー
当社のターボジェネレーターで作成された素晴らしい作品をご覧ください。ビジュアルをクリックしてプロンプトを表示し、同様の結果を再現できます。
Tiramisu AI画像から画像モデルの比較
元の画像

Change the clothes to sports
生成結果















Z-Image AI Turboの紹介:高速ジェネレーター

驚異的なスピード
高品質なビジュアルを数秒で生成します。ターボアーキテクチャは、作成プロセスのすべてのステップを最適化します。
LoRA互換
カスタムLoRAモデルで出力を微調整します。特定のスタイルを実現したり、ユニークなクリエイティブ要件に適応したりできます。
プロンプトの精度
テキスト記述の高度な理解。自然言語のプロンプトで、イメージ通りのものを正確に取得します。
Z-Image AI Turboジェネレーターの利点
並外れた速度と柔軟性を備えたプロフェッショナルグレードの生成ツールにアクセスできます。
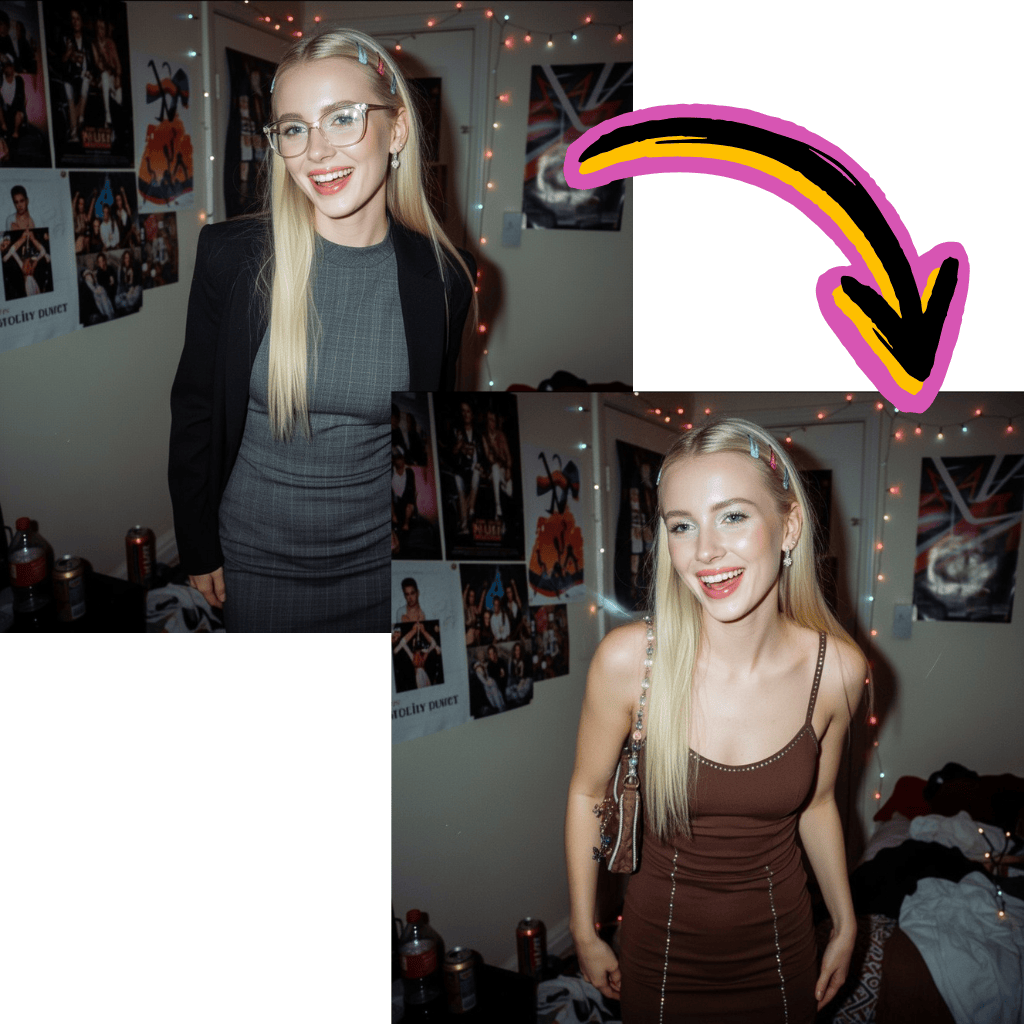
無料で開始
支払いをせずに作成を開始できます。ターボジェネレーターを探索するためのサインアップの壁や隠れた料金はありません。
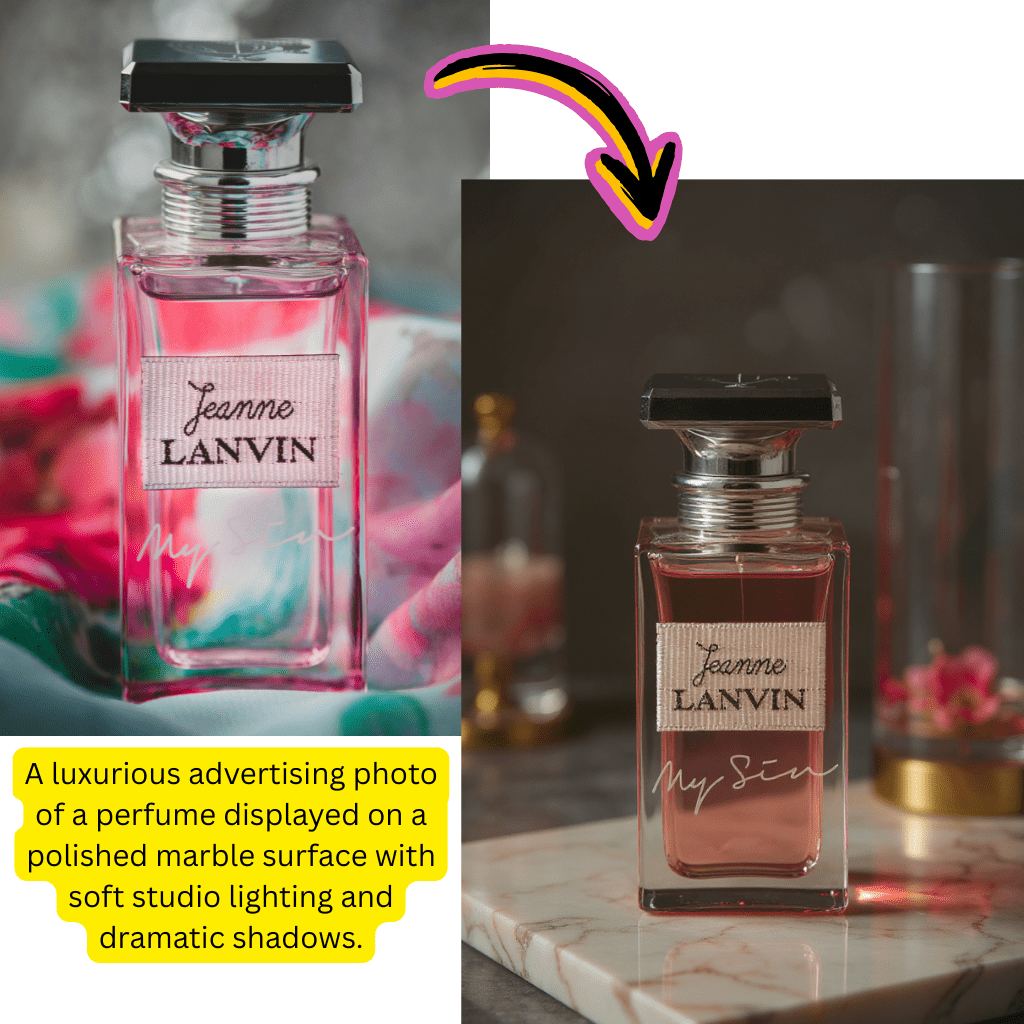
Alibabaテクノロジー
最先端の研究に基づいて構築されています。エンタープライズグレードのインフラストラクチャとモデル最適化の恩恵を受けられます。

ComfyUI対応
ComfyUIワークフローとシームレスに統合します。ベースモデルをダウンロードして、パイプラインをカスタマイズできます。

マルチフォーマット出力
さまざまな解像度と形式でエクスポートできます。ソーシャルメディア、印刷、またはプロフェッショナルなプロジェクトに最適です。
Z-Image AI生成の簡単なステップ
直感的なワークフローでプロフェッショナルなビジュアルを作成します。

プロンプトを入力
作成したいものを自然言語で説明してください。

設定を調整
アスペクト比、品質レベル、オプションのLoRAモデルを選択します。

即座に生成
生成をクリックして、ターボモデルがあなたのビジョンを作成するのを見てください。

結果をダウンロード
お好みの形式と解像度で作品を保存します。
Z-Image AI Turboの完全な機能
この強力なジェネレーターで利用可能なツールの完全なスイートを探索してください。
テキストから画像へ
テキストプロンプトを素晴らしい作品に変換します。ビジョンを説明すると、それが即座に具現化されるのを見てください。
画像から画像へ
ターボモデルで既存の画像を変形させます。構図を維持しながら新しいスタイルを適用します。
LoRA統合
特別な出力のためにカスタムLoRAウェイトをロードします。ユニークな美学のためにモデルをトレーニングまたはダウンロードします。
ワークフローサポート
ComfyUI互換性で複雑なパイプラインを構築します。高度な結果のために操作を連鎖させます。
バッチ処理
複数のバリエーションを同時に生成します。クリエイティブな方向性を素早く探るのに最適です。
品質プリセット
速度と詳細の間で選択します。特定のユースケースに合わせて設定を最適化します。
世界中のクリエイターに信頼されるZ-Image AI
成長するビジュアルコンテンツクリエイターのコミュニティに参加しましょう。
アクティブユーザー
50万人以上
クリエイターが毎日ツールを使用
作成された作品
2000万以上
正常に生成されたビジュアル
平均速度
5秒未満
ターボ生成時間
Tiramisu AI の価格
あなたのAI創作ニーズに最適なプランをお選びください。
Lite
20%オフ1日わずか$0.25
36,000クレジット前払い =
- •最大7,200枚以上のAI画像
- •最大850本以上のAI動画
- •1日平均20枚のAI画像または3本のAI動画
オールインワンマルチモデルサポート
含まれる内容
- テキストから画像へ
- 画像から画像へ
- テキストから動画へ
- 画像から動画へ
- 10種類以上の基本AIモデル
- 最大1080p解像度
- 基本フィルター&スタイル
- 標準速度
- 12ヶ月間有効
- ✓年間$24の節約
- ✓≈ 2.4ヶ月分無料
- ✓全クレジット前払い
年額$95.76で請求
Pro
1日わずか$0.38
90,000クレジット前払い =
- •最大18,000枚以上のAI画像
- •最大2,142本以上のAI動画
- •1日あたり50枚のAI画像または6本のAI動画
オールインワン高度なAIスイート
含まれる内容
- テキストから画像へ
- 画像から画像へ
- テキストから動画へ
- 画像から動画へ
- 20種類以上の高度なAIモデル
- 最大4K解像度
- 優先キュー(2倍速)
- 高度なフィルターライブラリ
- 商用ライセンス
- ウォーターマークなし
- 優先サポート
- 12ヶ月間有効
- ✓年間$95.91の節約
- ✓≈ 4.8ヶ月分無料
- ✓全クレジット前払い
年額$143.76で請求
Max
50%オフ1日わずか$1.1
360,000クレジット前払い =
- •最大72,000枚以上のAI画像
- •最大8,571本以上のAI動画
- •1日あたり200枚のAI画像または24本のAI動画
エンタープライズグレードのAI創作プラットフォーム
含まれる内容
- すべての生成タイプ
- すべてのAIモデル + ベータアクセス
- 最大8K解像度
- ウルトラ優先(5倍速)
- バッチ生成(50枚の画像)
- 高度な動画モデル
- カスタムAIトレーニング
- 専任マネージャー
- 完全な商用権利
- 24時間365日プレミアムサポート
- 12ヶ月間有効
- ✓年間$419.76の節約
- ✓≈ 6ヶ月分無料
- ✓全クレジット前払い
年額$419.76で請求
Z-Image AIに関するよくある質問
当社のターボジェネレーターの使用について知っておくべきことすべて。
Z-Image AIとは何ですか?どのように機能しますか?
これはAlibabaによって開発されたテキスト画像生成AIで、高度なディープラーニングを使用してテキストプロンプトを高品質なビジュアルに変換します。ターボバリアントは速度に最適化されており、数分ではなく数秒で結果を提供します。テキスト記述を分析し、意味を理解し、拡散ベースのアーキテクチャを通じて対応するビジュアルを生成します。
Z-Image AI Turboは他のモデルと比べてどれくらい速いですか?
ターボバリアントは通常3〜5秒でビジュアルを生成しますが、これは15〜30秒かかる標準的な拡散モデルよりも大幅に高速です。この速度の最適化は、Alibabaの研究チームによって開発されたアーキテクチャの改善と効率的な推論技術によるもので、迅速な反復とリアルタイムのクリエイティブワークフローに最適です。
Z-Image AIを画像編集(画像から画像へ)に使用できますか?
はい、テキストから画像への生成に加えて、既存の画像をアップロードしてテキストプロンプトを使用して変換することができます。これにより、元の構図を維持しながら、スタイルを変更したり、要素を修正したり、芸術的な効果を適用したりできます。モデルは、一貫性のある変換を生成するために、入力画像とテキスト指示の両方を理解します。
Z-Image AIモデルのユニークな点は何ですか?
いくつかの要因がこのモデルを際立たせています:品質を損なうことのない並外れた生成速度、正確な結果のための強力なプロンプト理解、さまざまなアスペクト比と解像度のサポート、LoRAファインチューニングとの互換性、シームレスなComfyUI統合です。速度と品質のバランスにより、制作ワークフローにとって特に価値があります。
Z-Image AIジェネレーターは無料で使用できますか?
無料のクレジットを使用して、無料でビジュアルの生成を開始できます。これにより、コミットする前にすべての機能を探索し、品質を評価できます。プレミアムティアでは、追加のクレジット、優先処理、高解像度の出力、および使用量の多いプロフェッショナルユーザー向けの高度な機能が提供されます。
Z-Image AIの効果的なプロンプトを作成するにはどうすればよいですか?
明確な被写体の説明から始めて、スタイル、雰囲気、技術的な詳細を追加します。例:「夕暮れ時の静かな日本庭園、柔らかな金色の光、散る桜、フォトリアリスティックなスタイル、詳細な葉」。欲しいものを具体的に記述しますが、過度に複雑なプロンプトは避けてください。モデルは自然言語と芸術的な用語によく反応します。
Z-Image AIはLoRAモデルをサポートしていますか?
はい、LoRA(Low-Rank Adaptation)モデルは完全にサポートされています。事前トレーニングされたLoRAウェイトを使用して、特定のスタイル、キャラクターの一貫性、または芸術的な効果を実現できます。これは、ブランドの一貫性を維持したり、キャラクター中心のコンテンツを作成したり、複数の生成にわたって特定の芸術的スタイルを複製したりするのに特に役立ちます。
Z-Image AIをComfyUIと統合するにはどうすればよいですか?
ベースモデルとターボバリアントは、ComfyUIと互換性のある形式でダウンロードできます。カスタムワークフローの構築、複数の操作の連鎖、条件付けの追加、ControlNetの使用、および他のノードとの統合が可能です。当社のドキュメントには、ローカル展開用のワークフロー例とGGUFモデルファイルが用意されています。
Z-Image AIでカスタムワークフローを作成できますか?
もちろんです。上級ユーザー向けに、モデルはComfyUIなどの一般的なワークフローツールと統合されます。生成、アップスケーリング、インペインティング、後処理を組み合わせたマルチステップパイプラインを作成できます。この柔軟性により、すべてのステップを正確に制御する必要がある複雑な制作パイプラインに適しています。
Z-Image AIはどのようなサイズと形式をサポートしていますか?
ジェネレーターは、1:1、16:9、9:16、4:3、3:4など、複数のアスペクト比をサポートしています。出力解像度は、サブスクリプションティアに応じて512pxから2048pxの範囲です。エクスポートはJPG、PNG、WebP形式で利用可能です。モデルは柔軟なアーキテクチャのおかげで、さまざまなサイズを効率的に処理します。
Z-Image AI Turboはどのようにして高速な生成を実現していますか?
ターボバリアントは、いくつかの最適化技術を使用しています。品質を維持しながらの拡散ステップの削減、最適化されたニューラルネットワークアーキテクチャ、効率的なアテンションメカニズム、および合理化された推論パイプラインです。これらの改善により、モデルは標準バージョンと同等の品質をわずかな時間で生成できます。
Z-Image AIジェネレーターの最適なユースケースは何ですか?
人気のある用途には、ソーシャルメディアコンテンツの作成、マーケティングビジュアル、コンセプトアート、製品モックアップ、イラストの下書き、ゲームアセット、クリエイティブな探索などがあります。速度が速いため、素早く反復する必要があるブレーンストーミングセッションに最適です。プロのクリエイターは、クライアントへのプレゼンテーションや迅速なプロトタイピングに使用しています。
Z-Image AIはStable Diffusionと比べてどうですか?
どちらも強力な拡散ベースのモデルですが、強みが異なります。ターボバリアントは速度と使いやすさを優先していますが、Stable Diffusionは広範なコミュニティリソースとカスタマイズオプションを提供しています。多くのクリエイターは、プロジェクトの要件に応じて両方を使用しています。当社のプラットフォームは、ローカルセットアップの要件なしに、アクセスしやすいクラウドベースの生成を提供します。
Z-Image AIの出力を商用利用できますか?
はい、当社のプラットフォームで生成された作品は、マーケティング、製品、出版物、クライアントワークなどの商用目的で使用できます。出力の権利はあなたが保持します。さまざまなサブスクリプションティアの商用ライセンスと帰属要件に関する具体的な詳細については、利用規約を確認してください。
Z-Image AIベースモデルのダウンロードとは何ですか?
ローカル生成を好むユーザーのために、ベースモデルのウェイトは、safetensorsやGGUFなどの標準形式でダウンロードできます。これらは、ComfyUI、Automatic1111、またはその他の互換性のあるインターフェースで使用できます。ローカル展開では、適切なハードウェアが必要ですが、使用ごとのコストなしで無制限に生成できます。
Z-Image AIはモバイルデバイスで動作しますか?
当社のWebインターフェースは完全にレスポンシブであり、スマートフォンやタブレットで動作します。すべての処理はクラウドで行われるため、強力なハードウェアは必要ありません。サイトにアクセスし、プロンプトを入力して、インターネットにアクセスできる任意のデバイスからビジュアルを生成するだけです。結果はデバイスのギャラリーに直接ダウンロードできます。
Z-Image AIはさまざまな芸術的スタイルをどのように扱いますか?
モデルは多様な視覚データでトレーニングされており、フォトリアリスティック、アニメ、油絵、水彩画、デジタルアート、3Dレンダリングなど、さまざまな芸術的スタイルを理解しています。プロンプトで希望のスタイルを指定するか、より一貫したスタイルの適用のためにLoRAモデルを使用してください。スタイルキーワードを試すと、興味深い結果が得られることがよくあります。
Z-Image AIのRedditコミュニティはありますか?
はい、活発なコミュニティがRedditやその他のプラットフォームで技術について議論し、作品を共有し、プロンプトを交換しています。これらのコミュニティは、高度なプロンプト技術を学び、新しいLoRAモデルを発見し、問題をトラブルシューティングし、他の人が作成したものからインスピレーションを得るための貴重なリソースです。関連するサブレディットを検索して会話に参加してください。